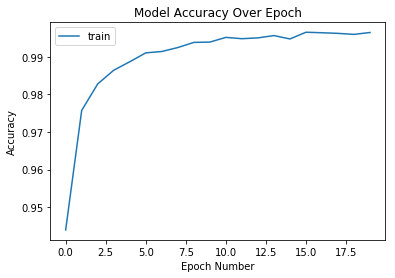
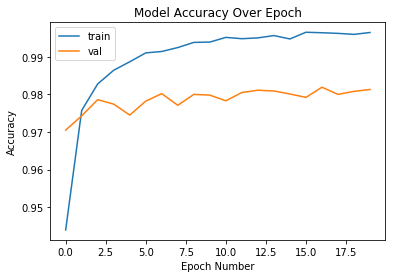
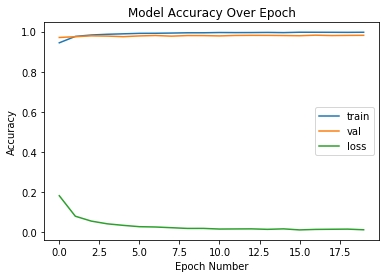
{'epoch': [0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19],
'history': {'acc': [0.9439666666666666,
0.9757333333333333,
0.9827833333333333,
0.9864166666666667,
0.9886666666666667,
0.9910333333333333,
0.9914,
0.99245,
0.9938166666666667,
0.9939,
0.99515,
0.9948,
0.9950166666666667,
0.9956333333333334,
0.9947333333333334,
0.9965166666666667,
0.9963833333333333,
0.9962166666666666,
0.99595,
0.99645],
'loss': [0.1827596818920225,
0.08079896697839722,
0.05645396511411139,
0.04291815567353721,
0.03526910000597515,
0.02873079521368248,
0.02715607473684601,
0.023650182965393438,
0.020055528101623546,
0.02019607128013062,
0.016955279541049723,
0.017472221146037314,
0.017864977817751575,
0.015457480643335983,
0.017869793417473495,
0.012631182595215281,
0.015135916414613901,
0.015882995463786898,
0.016569432756344288,
0.013335457366452594],
'val_acc': [0.9705,
0.9743,
0.9786,
0.9774,
0.9745,
0.9782,
0.9802,
0.9771,
0.98,
0.9798,
0.9783,
0.9805,
0.9811,
0.9809,
0.9801,
0.9792,
0.9819,
0.98,
0.9808,
0.9813],
'val_loss': [0.09286645495379343,
0.08266143489209934,
0.069480553943431,
0.08320518101718044,
0.09206652115154429,
0.08190068501315655,
0.08067529291427782,
0.11358439496830543,
0.10833151409866154,
0.10160923933375093,
0.11671308373045626,
0.10255490619101375,
0.10387474813488247,
0.11728941089477675,
0.11347036018394005,
0.13906407877868832,
0.12108565404413693,
0.120797497302599,
0.1309188434239974,
0.13095201672244552]},
'model': <keras.engine.sequential.Sequential at 0x7fb0320f3400>,
'params': {'batch_size': 32,
'do_validation': True,
'epochs': 20,
'metrics': ['loss', 'acc', 'val_loss', 'val_acc'],
'samples': 60000,
'steps': None,
'verbose': 1},
'validation_data': [array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], dtype=float32),
array([[0., 0., 0., ..., 1., 0., 0.],
[0., 0., 1., ..., 0., 0., 0.],
[0., 1., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], dtype=float32),
array([1., 1., 1., ..., 1., 1., 1.], dtype=float32)]}